목차: Context Engineering, Sessions & Memory
- Introduction
- Context Engineering (컨텍스트 엔지니어링)
- Session
- 프로덕션 진출 (Production Readiness)
- Memory (기억 / 장기 메모리)
AI Agents Intensive:ContextEngineering:Sessions, Memory
이번에 Kaggle 에서 진행하는 AI Agents Intensive 에서 참고한 ContextEngineering:Sessions, Memory를 정리한 것이다!
아래는 본문
Whitepaper: Context, Engineering, Sessions and Memory
내가 만들고 있는 강남대학교 챗봇에서 여기서 세션관리와 메모리에관한 인사이트를 얻고자 한다.
현재 내가 직면하고 있는 문제는
- SubAgnet 간 전환시 사용자에게 전환여부를 묻고있는것.
- 이제 로그인 기능을 만들어야 하는데 사용자별 세션과 맥락, 데이터를 가지고 있어야 한다! -> 이것의 효율적인 관리는 어떻게 하면 좋을까?
이 두가지다. 일단 이것을 유의하며 읽어보겠다.
Introduction
컨텍스트 엔지니어링: 정보를 동적으로 조합하고 관리하는 프로세스 LLM의 컨텍스트 창 내에서 상태저장
세션: 상담원과의 전체 대화를 위한 컴테이너로, 대화의 연대순 역사와 에이전트의 작업을 기억합니다.
메모리: 장기 지속성, 여러 세션에걸친 정보를 통해 지속적이고 개인화된 경험을 제공합니다.
컨텍스트 엔지니어링 (Context Engineering)
LLM은 본질적으로 상대 비저장입니다. 훈련 데이터 외에도 추론과 인식, 단일 API 호출의 컨텍스트 창 내에서 제공된 정보로 제한됩니다.
따라서 AI에이전트가 운영, 개인화를 위해 이러한 문제를 해결해야합니다.
상호작용을 기억하고, 핛브하고, 개인화할 수 있는 상태저장적이고 지능적인 에이전트를 위해 개발자는 대화의 모든 전환에 대해 이 컨텍스트를 구성해야 합니다. 이 동적 어셈블리와 LLM에 대한 정보 관리를 컨텍스트 엔지니어링이라고 합니다.
이 개념은 프롬프트 엔지니어링에서 진화한 개념입니다! 프롬프트 엔지니어링은 최적의 시스템 지침을 만드는데 중점이되지만 Context Engineering은 전체 페이로드를 처리하여, 상태인식 사용자, 대화기록 및 외부데이터를 기반으로 프롬프트를 동적으로 구성합니다.
LLM 에이전트는
• 계속 변하는 대화/상황(세션)
• 장기 기억(메모리)
• RAG 같은 외부 지식
을 동적으로 골라서 맥락으로 넣어줘야 하는데, 컨텍스트 창은 한계가 있고, 커지면 성능도 떨어지니 이걸 어떻게 잘 관리하느냐가 핵심 과제다.

에이전트에 대한 컨택스트 관리 흐름이다!
- 컨텍스트 가져오기: 에이전트는 사용자 메모리,RAG와 같은 컨텍스트를 검색하는 것으로 시작한다.
- 컨텍스트 준비: 에이전트 프레임워크는 전체 프롬프트를 동적으로 구성합니다. -> 맥락이 준비되기 전까지는 Agent를 진행할 수 없습니다.
- LLM및 도구 호출: 에이전트는 LLM과 필요한 도구를 반복적으로 호출합니다
- 컨텍스트 업로드: 턴 중에 수집된 새 정보는 기억에 업로드 됩니다 보통 이는 백그라운드 프로세스인 경우가 많습니다. 메모리 통합 또는 기타 사후처리는 비동기적으로 발생합니다.
따라서 두가지 중요한 개념이 나오는데 바로 세션과 메모리(기억)이다.
세션은 책상서랍에 비유하고, 메모리는 메모장에 비교한다. 작업을 막 하면서 책상위나 서랍에 어지럽게 정보들이 쌓여있고 작업이 끝나면 이것들을 하나하나 정리하며 매모를 남긴다. 이렇게 효과적인 에이전트는 만들어진다.
따라서 Context Engineering에 대한 이 높은 수준의 개요를 기반으로 이제 두가지 핵심을 탐색할 수 있습니다.
바로 Session & Memory
Session
Context Engineering 의 기본요소는 세션으로, 즉각적인 대화 기록 및 작업 기억입니다. 모든 세션에는 다음 두가지 주요 구성요소가 포함되어 있습니다.
- 연대순 이력 (이벤트) Event
- 에이전트의 작업 기억(상태) State
이벤트
이벤트는 대화의 구성 요소입니다, 사용자 입력(User input), 상담원 응답(agnet response), 도구호출(tool coll) 및 출력(tool output)
대화가 진행됨에 따라 Agent는 세션에 이벤트를 추가합니다. 또한 에이전트의 논리에 따라 상태를 변경할 수 있습니다.
상태(State)
세션은 단순한 대화기록 외에 "작업 메모리"같은 구조화 된 데이터를 같이 가지고 있을 수 있다.
- 장바구니에 담긴 상품 목록
- 특정 함수 호출 중간 단계
- 현재 쿼리 분석 결과
이런 데이터들이 state 로 저장된다.
따라서 대화가 진행될수록 이벤트가 더 쌓이고, state 도 필요에 따라 계속 수정된다.
이런 구조는 Gemini API의 Content List 구조와 비슷하다.
- role (user/assistant/tool)
- parts(메시지 구성요소)
로 구성되는 것처럼
contents = [ { "role": "user",
"parts": [ {"text": "What is the capital of France?"} ] },
{ "role": "model",
"parts": [ {"text": "The capital of France is Paris."} ] } ]`
response = client.models.generate\_content
(
model="gemini-2.5-flash",
contents=contents
)프레임워크 및 모델간 차이
핵심 아이디어는 비슷하지만 서로다른 에이전트 프레임워크(Google의 ADK,랭체인 등)은 세션과 이벤트, 상태를 구현하는 방식은 서로 다릅니다.
에이전트 프레임워크는 LLM을 위한 대화기록과 상태를 유지하고, 이 컨텍스트를 사용해 LLM 요청을 구성하며 LLM 응답을 파싱하고 저장하는 역할을 맡습니다.
따라서 에이전트 프레임워크는 개발자 코드와 LLM 사이의 범용 번역기처럼 동작합니다.
개발자인 당신은 각 대화 턴마다 프레임워크가 제공하는 일관된 내부 데이터 구조를 사용하기만 하면 되고,
프레임워크는 이 구조들을 LLM이 요구하는 정확한 포맷으로 변환하는 중요한 작업을 처리한다.
이러한 추상화는 강력한데, 그 이유는 특정 LLM에 종속되지 않도록 에이전트의 로직을 LLM 자체와 분리해주기 때문이다.
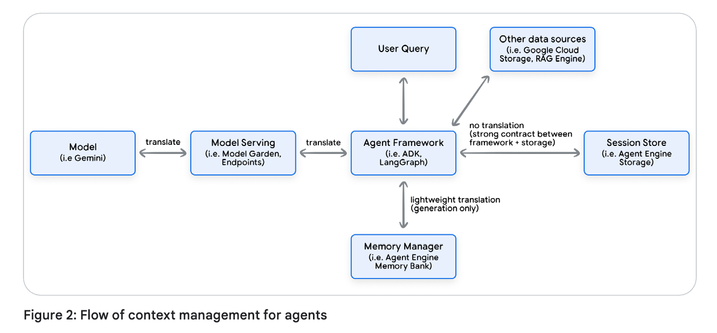
궁국적인 목표는 LLM이 이해할 수 잇는 요청을 생성하는 것입니다.
Gemini 모델에서는 이것이 List{Content}형식이다. role 과 parts 프레임워크는 API 호출을 하기 전에, 내부객체로부터 데이터를 가져와 해당 Content 객체의 role과 parts로 자동으로 매핑해준다.
결국, 프레임워크는 개발자에게는 안정적인 내부 API를 제공하면서,
뒤에서는 서로 다른 LLM들이 가진 복잡하고 다양한 외부 API들을 대신 처리해주는 것이다.
LangGraph는 공식적인 session 객체가 없다. 대신 state자체가 곧 session이다. 이들은 포괄적인 state객체를 사용한다. 대화기록뿐 아닌 모든 작업데이터를 가지고 있다. 랭그래프의 state는 변경(mutable) 가능한 구조다. history compaction과 같은 전략을 통해 기록을 수정할 수 있다.
Multi Agent systems의 세션
멀티에이전트 시스템에선 여러 에이전트가 협력한다. 이들이 효과적으로 작업하려면 정보를 잘 공유해야한다.
아래 다이어그램에서 보듯, 시스템의 아키텍쳐는 에이전트들이 정보를 공유하기위해 사용하는 통신 패턴을 정의한다.
이 아키텍처에서 핵심 구성요소 중 하나가 바로 세션 히스토리를 어떻게 처리하는가 이다.

이 아키텍쳐 패턴들을 보기전, 세션 히스토리는 LLM에 보내는 컨텍스트와는 다르다는 점을 구별해야한다.
세션 히스토리는 전체 대화를 그대로 담아두는 영구적이고 완전한 기록이다.
반면 컨텍스트는 LLM에 특정 턴을 위해 보배는 정제된 정보 묶음이다.
멀티 에이전트 시스템의 세션 히스토리를 처리할때 두가지 주요 방식이 있다.
- 모든 에이전트가 하나의 통합된 로그에 기록하는 공유 히스토리 모델,
- 각 에이전트가 자신만의 기록을 유지하는 개별 히스토리 모델
어떤 방식을 택할지는 작업의 성격과 에이전트 간 원하는 협업 방식에 따라 결정된다.
공유 히스토리 모델은 한 에이전트의 출력이 다음 에이전트의 입력이 되는 Single source of truth 이 필요한 경우에 가장 적합하다!
이를 사용하더라도 서브 에이전트가 로그를 LLM에 전달하기 전 필터링하거나 어떤 에이전트가 어떤 이벤트를 생성했는지 구분하는 라벨을 추가하는 등의 전처리를 수행할 수 있다.
개별 히스토리 모델은 각 에이전트가 단독으로 자신의 개인 대화 기록을 유지하며, 다른 에이전트에게는 마치 블랙박스처럼 동작한다. 다른 에이전트는 이를 볼 수 없다. 서로간 소통은 최종 출력을 명시적으로 메시지 형태로 교환하는 방식으로 이루어진다.
결과만 공유하는 방식이다. 이는 다음중 하나로 구현된다.
- Agent as a Tool: 한 에이전트를 도구처럼 호출하여 입력을 주고, 그 결과로 완전히 정리된 최종출력만 받는 방식
- Agent to Agent Protocal(A2A): 에이전트들이 서로 직접 메시지를 주고받기 위한 구조화된 프로토콜을 사용.
내 챗봇의 경우 공유 히스토리 모델을 사용해야 한다고 생각한다. 또는 RootAgent가 다른 에이전트들을 tool 처럼 호출하는 방식으로 해야
1번 문제가 해결될거 같다.
여러 에이전트 프레임워크 간의 상호운용성
에이전트 프레임워크를 사용하면 LLM과 에이전트를 분리해주는 추상화를 진행하는데 이는 동시에 다른 에이전트 프레임워크를 사용하는 데이전트들과의 연결도 단절시키기 때문이다.
이 단절은 Persistence layer 저장 계층에서 더욱 강화된다. Session 저장 모델은 보통 DB스키마가 프레임워크 내부 객체구조와 연결이 되어있어서
LangGraph로 만든 에이전트는 ADK기반 에이전트가 저장한 세션과 Event 객체를 이해할 수 없다.
이를 해결하기 위해 A2A 프로토콜을 개발했다.
이 패턴을 사용하면 에이전트들이 메시지를 주고받을 수 있다. 하지만 풍부한 컨텍스트 상태를 공유하는 문제는 해결하지 못한다.
따라서 세션 이벤트를 포함한 A2A메시지는 활용 가능하려면 번역 계층이 필요하다.
추가로 더 강력한페턴은: 프레임워크와 무관한 Memory계층에 공유지식을 추상화해 저장하는 구조가 있다.
Session 저장소는 특정 프레임워크의 row객체를 그대로 보관하고
Memory 계층은 처리되고 정규화된 정보를 저장하도록 설계한다.
이들은 보통 문자열 또는 딕셔너리 형태로 저장되며, 어떤 프레임워크 내부 객체 모델에도 묶이지 않게 한다.
프로덕션 진출
에이전트를 프로덕션 환경으로 이동할때, 세션 관리 시스템은 단순한 로그가 아닌 엔터프라이즈급 서비스로 발전해야 한다.
주요 고려 사항은 보안 및 프라이버시, 데이터 무결성, 성능이라는 세 가지 핵심 영역에 속한다.
Agent Engine Session와 같은 관리형 세션 스토에서는 이러한 프로덕션 요구사항을 충족하도록 설계되어있다.
보안 및 개인정보 보호
데이터 무결성 및 수명주기 관리
성능 및 확장성
긴 컨텍스트 대화관리
긴 대화를 관리할 때는 여러 가지 절충점과 최적화 전략이 필요하다.
대화가 길어질수록 토큰사용량이 계속 커진다. 속도가 중요한 서비스에서는 다음 문제가 생긴다.
- 컨텍스트 윈도우 한계
모든 LLM은 한번에 처리할 수 있는 최대 길이가 정해져 있다. - 비용 증가
대부분의 LLM은 보낸 토큰과 받은 도큰수에 비용이 발생한다. - 응답 지연
모델이 받아야 하는 텍스트가 늘어날 수록 처리시간이 느려지고, 결과적으로 답이 오는 속도도 느려진다. - 품질 저하
맥락안에 불필요한 정보가 함께 늘어난다.
따라서 긴 대화 기록은 Compaction(압축) 전략으로 줄여서 컨텍스트 윈도우안에 맞추고 API비용과 지연을 줄인다.
대표적인 압축방식은 다음과 같다
- 최근 N턴 유지하기: 최근 몇개의 대화를 남기고 이전 기록은 버린다.
- 토큰기반 잘라내기 : 최근 메시지부터 거꾸로 올라가며 토큰을 합산해서, 지정된 토큰 수를 넘지 않는 범위까지만 포함한다.
- 재귀적 요약 : 오래된 대화는 요약본으로 대체한다. 대화가 길어질 때마다 모델을 한번 더 호출해 오래된 부분을 요약하고 최신대화와 함께 모델에 제공한다.
Google ADK에선 내장 플러그인을 활용해 모델에 전달되는 컨텍스트길이를 제한할 수 있다.
from google.adk.apps import App
from google.adk.plugins.context_filter_plugin import ContextFilterPlugin
app = App(
name='hello_world_app',
root_agent=agent,
plugins=[
# 최근 10번의 호출과 가장 최신 사용자 질의만 유지
ContextFilterPlugin(num_invocations_to_keep=10),
],
)고급 대화 압축 전략은 비용과 지연시간을 줄이는 것이 목표이기 때문에 요약같은 고비용 작업은 반드시 비동기적으로 백그라운드에서 수행하고, 그 결과는 영구 저장을 한다.
또한 에이전트는 언제 압출할지 실행할지를 스스로 판단해야한다.
일반적으로 다음 세 가지 유형의 트리거 방식이 사용된다.
- 토큰수, 턴수 기준
- Time-Based: 사용자가 15~30분 동안 입력하지 않음 압축
- 작업/주제 종류 기반: 특정 작업이나 하위 목표가 끝났다고 에이전트가 판단하면 압축
예시
from google.adk.apps import App
from google.adk.apps.app import EventsCompactionConfig
app = App(
name='hello_world_app',
root_agent=agent,
events_compaction_config=EventsCompactionConfig(
compaction_interval=5, # 5턴마다 요약 실행
overlap_size=1, # 요약 시 이전 일부 메시지와 겹치는 구간 유지
),
)메모리 생성(Memory generation)
메모리 생성은 불필요한 데이터 속에서 지속적으로 보관할 가치가 있는 지식 만 뽑아내는 능력을 의미한다.
대표 사례로 대화 이력에서 정보를 추출하는 방법, 즉 session compaction을 소개한다.
Compaction은 전체 대화 로그를 그래도 유지하는 대신, 중요한 사실과 요약만 남긴다.
Memory
메모리와 세션은 강하게 연결되어있다. 세션은 메모리를 만들어내는 주요 데이터의 원천이고, 메모리는 세션 크기를 관리하는 핵심 전략이 된다.
메모리란 대화나 데이터 소스에서 의미 있는 정보만 추려낸 요약본이다.
전체 기록을 담는것이 아닌 향후 중요한 문맥을 유지할 수 있도록 핵심만 압축해 저장한 스냅샷이다.
Memory Manager
메모리 관리자는 독립된 서비스이며, Multi- Agent 환경에서 상호 운용성을 보장하느 닉반이 된다.
메모리 저장 형식도 프레임워크에 종속되지 않는 문자열이나, 딕셔너리같은 단순구조이다.
메모리가 중요한 이유?
메모리를 잘 저장하고 불러오는 기능은 고도화 된 지능형 에이전트를 만드는 핵심 요소다.
탄탄한 메모리 시스템은 단순한 챗봇을 넘어 더 똑똑하고 적응하는 에이전트를 가능하게 한다.
1) 개인화
사용자의 취향, 사실 정보, 이전대화를 기억해 미래 응답에 반영할 수 있다.
2) 컨텍스트 윈도우 관리
대화가 길어지면 메모리 시스템은 핵심 내용만 요약해 보관함으로써 문맥을 유지한다.
3) 데이터 마이닝 및 인사이트 도출
다수의 사용자 메모리를 집계도니 형태로 분석하면 패턴을 발견할 수 있다.
4) 에이전트의 자기 개선 및 적용
에이전트는 자신의 행동 패턴도 절차적 메모리로 남길 수 있다. 이 기록을 기반으로 점점더 나은 해결 방법을 스스로 학습할 수 있다.
절차적 메모리 Procedural Memory -> 더찾아봐야할듯
메모리 생성·저장·활용은 여러 컴포넌트가 협력해서 이루어진다
1) 사용자: 메모리의 원천이 되는 데이터를 제공한다.
2) 에이전트: 무엇을 어제 기억할지 결정한다.
3) 에이전트 프레임워크: 대화 히스토리에 접근하고 메모리 메니저와 통신하는 구조적 도구를 제공한다.
4) 세션 스토리지: 턴 단위의 원본 대화를 저장한다. 이 원본 기록이 메모리 메니저에 전달되어 요약,추출작업을 한다.
5) 메모리 메니저(Agent Engine Memory Bank)-> 메모리 저장, 조회,압축등 전 과정을 담당하는 핵심 구성요소!
메모리 매니저는 다음과 같은 기능을 수행한다:
• Extraction(추출): 원본 데이터에서 핵심 정보만 뽑아냄
• Consolidation(정제): 중복된 개념·사실을 합쳐 정리
• Storage(저장): 영구 저장소(DB)에 기록
• Retrieval(조회): 새 대화에서 사용할 관련 메모리를 불러옴

메모리 메니저는 단순한 백터 DB가 아니라 능동적으로 작동하는 시스템이란 사실이다.
Agent Engine memory Bank 같은 관리형 메모리 서비스는 메모리 생성부터 저장까지 전체 라이프 사이클을 모두 맡아 처리해주기 때문이다.

메모리는 RAG 와 비교되기도 한다.
비유를 하면 RAG 는 사서다. 방대한 백과사전, 문서가 있는 도서관에서 사용자의 쿼리에 대한 문서를 알려준다. -> 사용자가 누구인지는 중요하지 않다.
Memory 는 개인비서다. 사용자를 따라다니며 친밀한 기록을 남기고, 개인적이라 유저별로 완전히 분리한다.
Types of Memory
에이전트의 메모리는 정보가 어떻게 저장되었는지, 그리고 어떤 경로로 캡처되었는지에 따라 여러 형태로 나눌 수 있다.
이 다양한 메모리들은 함게 작동하며 사용자에 대한 깊이있는 문맥 이해를 만들어낸다.
메모리 기본 구성요소
- Content(콘텐츠) : 원본 대화나 데이터에서 추출한 실제 내용
콘텐츠는 구조화된 형태 또는 비구조화된 형태 둘 다 가능하다.
• 구조화된 메모리(Structured)
• 딕셔너리/JSON 같은 보편적 구조
• 스키마는 개발자가 정의
• 예: {"seat_preference": "Window"}
• 비구조화된 메모리(Unstructured)
• 자연어 문장 형태
• 예: "The user prefers a window seat." - Metadata(메타데이터)
• 메모리에 대한 추가 정보
• 보통 문자열로 관리
• 예: 메모리 고유 ID, 해당 메모리의 주인(owner) ID, 출처(source) 라벨 등.
Types of Information
connitive Science에서 가져온 분류로, 메모리는 크게 두 종류로 나뉜다.
1) Declarative Memory
에이전트가 명시적으로 말할 수 있는 정보들
- 사실
- 사건
- 사용자에 관한 정보
Semantic: 일반적 세계 지식
Entity/Episodic: 사용자와 특정 사건에 대한 정보
2) Procedural Memory
에이전트가 어떤 작업을 어떻게 수행하야 하는지에 관한 지식
ex)항공권 예약 시 어떤 순서로 툴을 호출해야 하는가?
이 메모리는 에이전트가 스스로 실행 행동의 정확도를 높일 때 사용된다.
Memory Organization Patterns(메모리 구성 방식)
메모리가 생성되면, 이제 어떻게 조직할지를 결정해야 한다.
1) Collections 패턴
• 사용자에 대한 여러 개의 독립적 자연어 메모리
• 이벤트, 요약, 관찰 등이 각각 개별 메모리로 저장
• 구조화는 느슨하지만 넓은 주제 탐색에 유용
2) Structured User Profile 패턴
• 명함(contact card)처럼 핵심적인 사용자 정보를 구조화하여 저장
• 이름, 취향, 계정 정보 등
• 빠른 조회에 최적
3) Rolling Summary 패턴
• 모든 정보를 하나의 긴 “마스터 요약문”으로 계속 업데이트
• 새로운 메모리를 계속 추가하는 대신 기존 요약을 갱신
• 긴 세션 기록을 압축하는 데 매우 효과적
Storage Architectures
1) Vector Database(벡터 DB)
• 메모리를 임베딩 → 벡터로 변환
• 의미 기반 검색(semantic search)
• 자연어 기반 메모리(“atomic facts”) 검색에 유리
2) Knowledge Graph(지식 그래프)
• 엔티티(node)와 관계(edge)로 메모리를 저장
• 복잡한 관계나 구조적 질의에 강함
• 예: “A는 B의 친구이고, B는 C의 동료이며…”
3) Hybrid (벡터 + 그래프)
• 그래프에 벡터 임베딩을 추가해
구조적 추론 + 의미 기반 검색을 모두 수행
• 가장 강력한 형태
Creation Mechanisms (메모리 생성 방식)
1) Explicit Memory (명시적 메모리)
사용자가 직접 “기억해줘”라고 요청
• 예: “10월 26일이 내 기념일이라고 기억해줘.”
2) Implicit Memory (암묵적 메모리)
사용자가 직접 요청하지 않아도 에이전트가 대화에서 암묵적으로 추출
• 예: “기념일이 다음 주라 선물을 사고 싶어.” → 기념일을 메모리로 저장
Memory Scope
메모리의 범위(scope)는 매우 중요하며, 다음 세 가지가 존재한다.
1) User-Level Scope (가장 흔함)
• 사용자별로 메모리를 유지
• 세션이 바뀌어도 계속 누적
• 개인화된 장기 문맥 형성
• 예: “사용자는 중간 좌석을 선호한다.”
2) Session-Level Scope (긴 대화 압축용)
• 특정 세션에서만 유효
• 대화 내용을 요약한 핵심 사실만 남김
• 예:
“사용자는 2025년 11월 7~14일 뉴욕→파리 항공권을 찾고 있으며, 직항과 중간 좌석을 선호한다.
3) Application-Level Scope (글로벌 메모리)
• 모든 사용자가 공유
• 민감 정보는 철저히 제거해야 함
• 주로 Procedural Memory(작업 절차)를 저장
• 예: “코드네임 XYZ는 어떤 프로젝트를 뜻함”
response = client.agent_engines.memories.generate(
name=agent_engine_name,
direct_contents_source={
"events": [
{
"content": types.Content(
role="user",
parts=[
types.Part.from_text("This is context about the multimodal input."),
types.Part.from_bytes(data=CONTENT_AS_BYTES, mime_type=MIME_TYPE),
types.Part.from_uri(file_uri="file/path/to/content", mime_type=MIME_TYPE)
]
)
}
]
},
scope={"user_id": user_id}
)Memory Generation: Extraction and Consolidation
메모리 생성은 원시 대화 데이터를 구조화도니 의미 있는 인사이트로 자동 변환하는 과정이다.
LLM이 중심이 되는 ETL 이다.
메모리 메니저가 LLM을 통해 스스로 판단하고 필요할 때 새로운 메모리는 생성하거나 수정,병합한다.
• DB 스키마 관리
• LLM 호출 체이닝
• 백그라운드 비동기 작업
같은 복잡한 작업을 모두 내부적으로 처리해주기 때문이다.
메모리 생성의 알고리즘
1) ingestion
클라이언트가 대화 기록같은 원본을 메모리 메니저에게 전달
2) Extraction&Filtering
메모리 메니져는 LLM을 사용해 원본 데이터에서 의미 있는 내용을 추출한다.
3) Consolidation
메모리 매니저가 새로 추출한 내용을 기존 메모리와 비교
• 기존 메모리에 병합할지(Merge)
• 기존 메모리를 삭제할지(Delete)
• 새로운 메모리를 생성할지(Create)
를 스스로 결정한다.
즉, LLM을 활용한 자기 수정(self-editing) 과정이다.
이 과정을 통해 사용자의 지식 베이스는
일관성, 정확성, 최신성을 유지하며 자연스럽게 진화한다.
4) Storage (저장)
이후로는 조금 더 이해하고 작성해야겠다.
이후에 있는 내용은 고급 관리이기때문에 아직 정리하기 어려워서 나중에 정리하도록 하겠다.
'AI > 공부' 카테고리의 다른 글
| 바이브 코딩 다음 단계, Harness Engineering: 에이전트 개발을 안정화하는 5가지 원칙 (0) | 2026.02.16 |
|---|---|
| SpecKit 완벽 가이드 - AI와 함께하는 스펙 주도 개발(SDD) (0) | 2026.01.03 |
| 📚 머신러닝과 딥러닝 완벽 정리 | 개념부터 모델 종류까지 한눈에 보기 (0) | 2025.03.21 |

